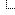


RE: Supermathematics and Artificial General Intelligence
September 5, 2017 at 4:55 am
(This post was last modified: September 5, 2017 at 5:14 am by ThoughtCurvature.)
(September 5, 2017 at 4:24 am)Alex K Wrote: I know something or other about how to do supersymmetry and superspace. What I don't understand is how you propose to use Grassmann variables in learning, because you don't say how.
Alex, at least, from ϕ(x;θ)Tw, or the machine learning paradigm:
In the machine learning regime, something like the following applies:
- Points maintain homeomorphisms, such that for any point p under a transition T on some transformation/translation (pertinently continuous, inverse function) t, p0 (p before T) is a bijective inverse for p1 (p after T); on t.
- Following the above, topologies maintain homeomorphisms, for any collection of points W (eg a matrix of weights), under some transition T on some transformation/translation sequence (pertinently continuous, inverse functions) s, W0(W before T) is a bijective inverse for W1(W after T); on s, where for any representation of W, determinants are non-zero.
- Now, topological homeomorphisms maintain, until linear separation/de-tangling, if and only if neural network dimension is sufficient (A small example: 3 hidden units at minimum, for 2 dimensional W)
- Otherwise, after maintaining homeomorphism at some point, while having insufficient dimension, or insufficient neuron firing per data unit, in non-ambient isotopic topologies that satisfy NOTE(ii) W shall eventually yield zero determinant, thus avoiding linear separation/unentangling. At zero determinant, unique solutions for scalar multiplications dissolve, when the matrix becomes non-continuous, or non-invertible.
- NOTE(i): Entangled is the point before which some unentangleable classes are unentangled/made linearly separable.
- NOTE(ii): Unique solutions in matrices are outcomes that resemble data sets; for homeomorphisms (topologies: where zero-determinant continuous invertible transformations/translations engender OR ambient isotopies: where positive/nonsingular determinants, nueron permutations, and 1 hidden unit minimum occurs, i.e for 1-dimensional manifold, 4 dimensions are required)
Chris Olah: "Neural Networks, Manifolds, and Topology"
Kihyuk Sohn et. al: "Learning to Disentangle Factors of Variation with Manifold Interaction"
FOOTNOTE:
You are correct though, I don't know much about supermathematics at all, but based at least, on the generalizability of manifolds and supermanifolds, together with evidence that supersymmetry applies in cognitive science, I could formulate algebra with respect to the deep learning variant of manifolds.
This means that given the nature of supermanifolds and manifolds, there is no law preventing ϕ(x;θ,
![[Image: ncrjUdkm.png]](https://i.imgur.com/ncrjUdkm.png) )Tw, some structure in euclidean superspace that may subsume pˆdata (real valued training samples).
)Tw, some structure in euclidean superspace that may subsume pˆdata (real valued training samples).